用数学统计的方法研究语言语音的规律
这篇内容摘自我研究生一年级写的论文《关系的逻辑分析:数学在艺术和设计中的应用》第三章《感受世界:语言系统背后的数学规律》。这篇文章,也是Tone-da项目研究的开端。
下方的这方图表是我统计英语中不同个数字母组成的词汇的个数制成的。左侧表格的纵栏第一列是每个词语中包含的字母的个数,第二列是由该数量个字母组成的词语的个数。将这两行数据画成折线图后,得到了右侧正态分布的曲线。按理来说,随着词语中字母个数的增长,能组成的词语的个数也会成指数函数(y=a^x)的模型进行增长,而不是呈正态分布的数学模型,所以这个结果是非常有趣的。
这条正态分布曲线的均值约为8.5,也就是说,在英语中,由8到9个字母组成的词汇个数是最多的。 那么,得出这一数据有什么意义呢?
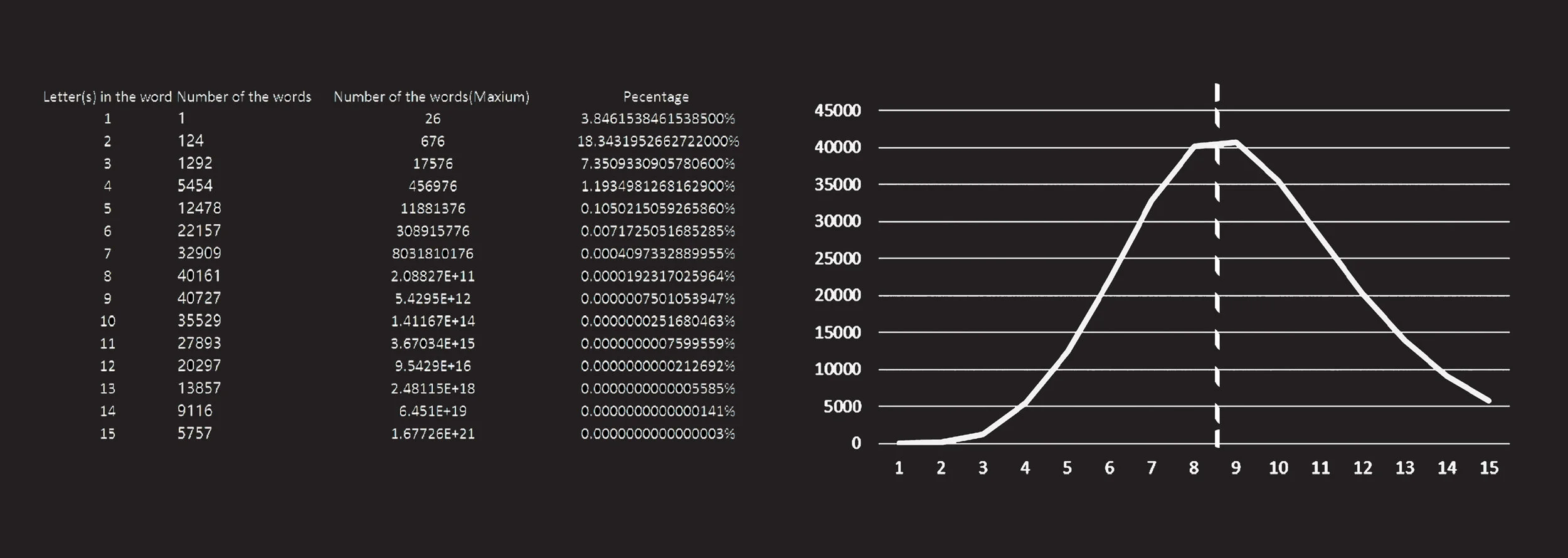
英语是一种表音语言,即语言的拼写便决定了它的发音。8到9个字母组成的词语,在发音上,大约是2-4个音节。也就是说,2-4个音节发音的词汇在英语中是最常见的。反观中文,汉字是一种意音文字,每一个文字便发一个单音。而中文中多数的词汇也是由2-4个字组成,也就是说,中文中大多数的词汇也是2-4个音节。
根据中英文词汇在发音长短上的相似性,我决定对这两种语言和语言学习进行更加深入的研究,从而也就有了之后Tone-da的项目。